创建生成准确结果的机器学习模型是一回事,但确保模型的可解释性——即理解模型为何生成特定结果的能力——则是另一回事。没有可解释性,模型就不适合需要理解和解释模型行为的应用场景。
机器学习中的可解释性揭示了模型做出特定决策的原因,从而使结果更易理解并增加透明度。为了提高新模型和现有模型的可解释性,模型开发者可以使用多种技术,包括线性回归、广义线性建模、决策树和本地可解释模型无关解释(LIME)。

机器学习中的可解释性是什么?
在机器学习中,可解释性是指理解模型为何做出某个决策的能力。例如,考虑一个将猫和狗的图像分类的简单模型。如果模型具有高度可解释性,用户就能理解模型在评估每张图像时进行的分类过程。
为什么可解释性很重要?
模型的可解释性对合规性和透明度、自定义模型行为和模型故障排除非常重要。
合规性和透明度
某些合规规定要求企业向用户解释自动化服务为何对其做出特定决策。例如,欧盟的GDPR要求算法决策的透明度。
自定义模型行为
模型越具可解释性,开发者就越容易自定义其行为。
模型故障排除
可解释性有助于解决模型问题,如预测不准确。
可解释性与可解释性
可解释性和解释性是相关的,但不可混为一谈。解释性是指预测模型在特定输入下的决策能力,而无需深入了解模型的内部工作。
确保机器学习模型可解释性的策略
新模型的可解释性
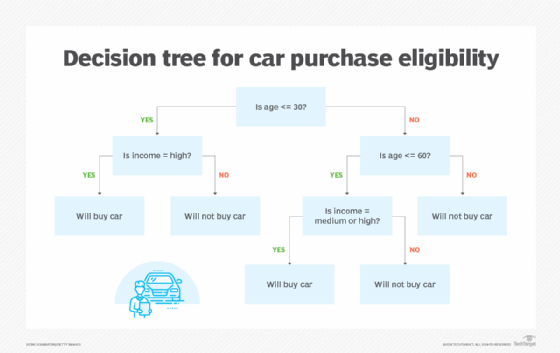
设计新模型时,使用操作简单、可预测的算法,如线性回归、广义线性建模和决策树。
现有模型的可解释性
对于现有模型,可以使用LIME等方法来增强其可解释性。LIME通过解释非可解释模型的结果来提高模型的透明度。
相关文章
© 版权声明
文章版权归作者所有,未经允许请勿转载。如有侵犯您的版权,请及时联系我们→侵删通道。

暂无评论...

全球实用网站,"Ctrl+D"收藏本站!

